The African Network Information Centre (AFRINIC) in collaboration with the Africa Network Operators Group (AfNOG) have proudly concluded the second AIS’21 virtual conference.
The event took place from 31 May to 4 June 2021 and was attended by 378 delegates from 55 countries.
The conference was enriched by technical sessions from renowned experts who delivered insightful presentations on topics such as IPv6, Blockchain Governance, Internet Routing security, Digital Inclusion among others.
The conference saw over seventy presentations that spun over 5 days. The Last day of the conference was dedicated to the AFRINIC Annual General Members Meeting.
The agenda also consisted of other notable pre-event sessions that took place from 24 - 28 May and included several AfNOG tutorials, the AFRINIC Government Working Group Meeting, the newcomers’ session and a session dedicated to Inclusivity and Diversity in the AFRINIC ecosystem.
Presentations and Daily Recaps
- We invite you to read all the session recaps: 31 May | 1 June | 2 June | 3 June | 4 June
- The Meeting agenda and slides are available here.
- Watch the videos for all the sessions here.
- Meeting statistics are available here.
The Platform
We learnt a lot from our past experience as this was our second time using the Meetecho platform. The overall experience was better than last year. The Organising Team was prepared and took several actions that led to the smooth running of the programme such as organising daily tests with speakers, moderators and MCs who could get acquainted with the platform. The coordination among staff, speakers, moderators and MCs also was well orchestrated.
The Meetecho platform provided a feature for speakers to upload their slides which was an additional option to sharing their screen, and this proved useful.
This time, we introduced several innovations such as a quiz competition during the breaks and for the first time we held an online cocktail online on a dedicated platform ‘’Spatial Chat’’. Those events were well received by our delegates and have set the benchmark for our upcoming AFRINIC and AIS events.
Another novelty, the AIS '21 Online Opening Ceremony was set on a hybrid format with our Chief Guest, HE Mr Augustin Kibassa the Minister of Posts, Telecommunications & ICT giving the Opening Speech live from Kinshasa in DRC.
However, we faced some technical challenges with the hybrid format as well as a bug was reported on the slide share functionality on 28 May during the newcomer’s session. There were some concerns also raised with regards to privacy issues on filling our online survey form and with meeting tokens during the AGMM.
We take with us the lessons learned as we shall strive to get better at these aspects for our future events.
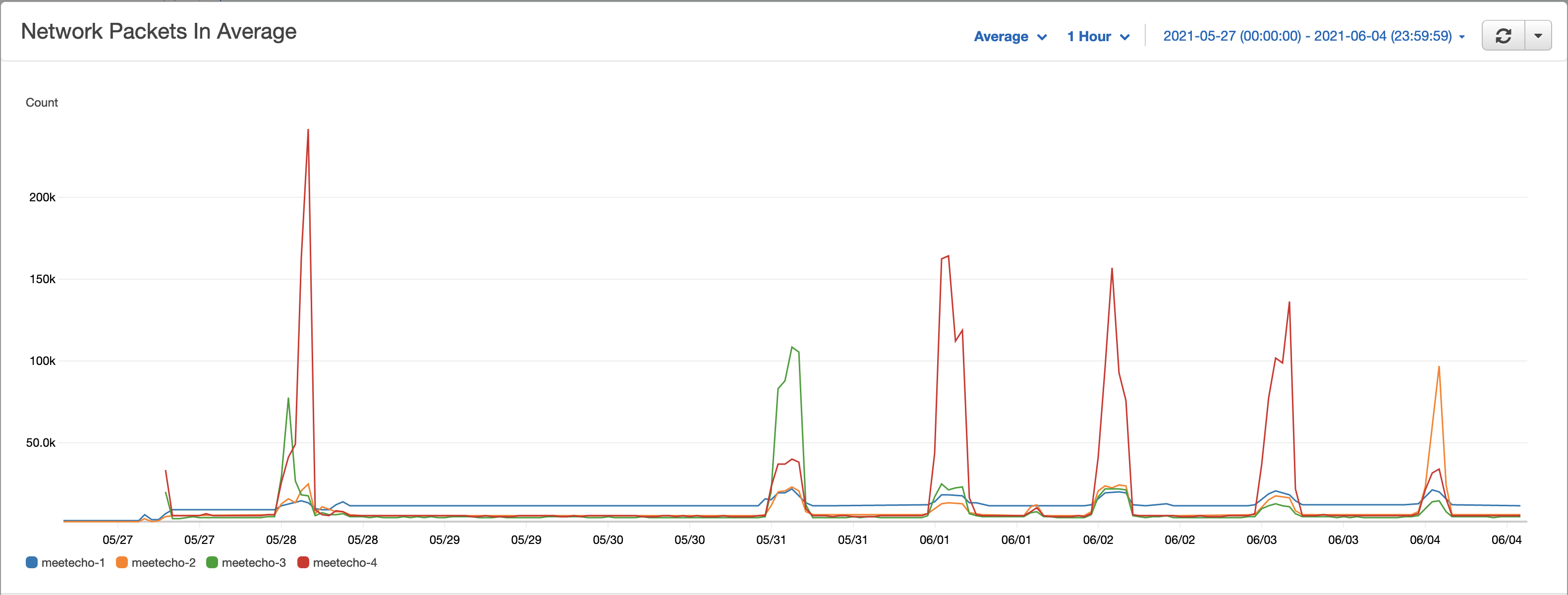
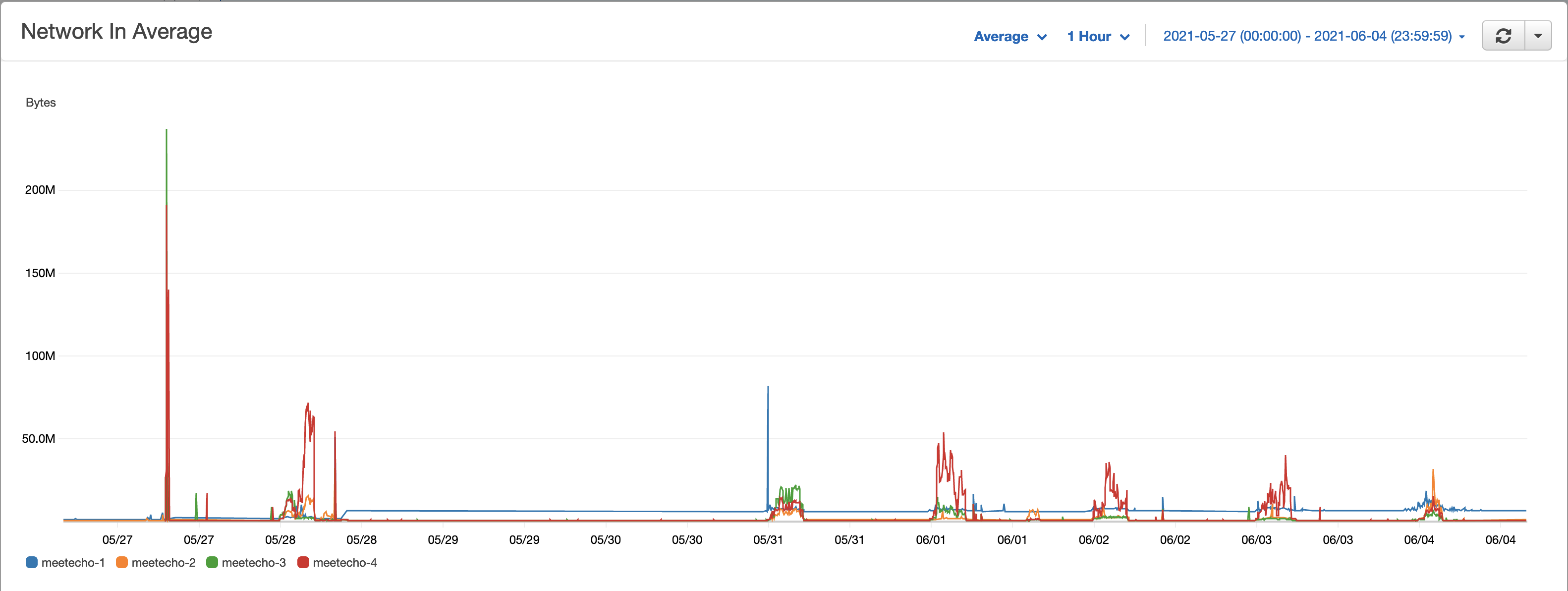
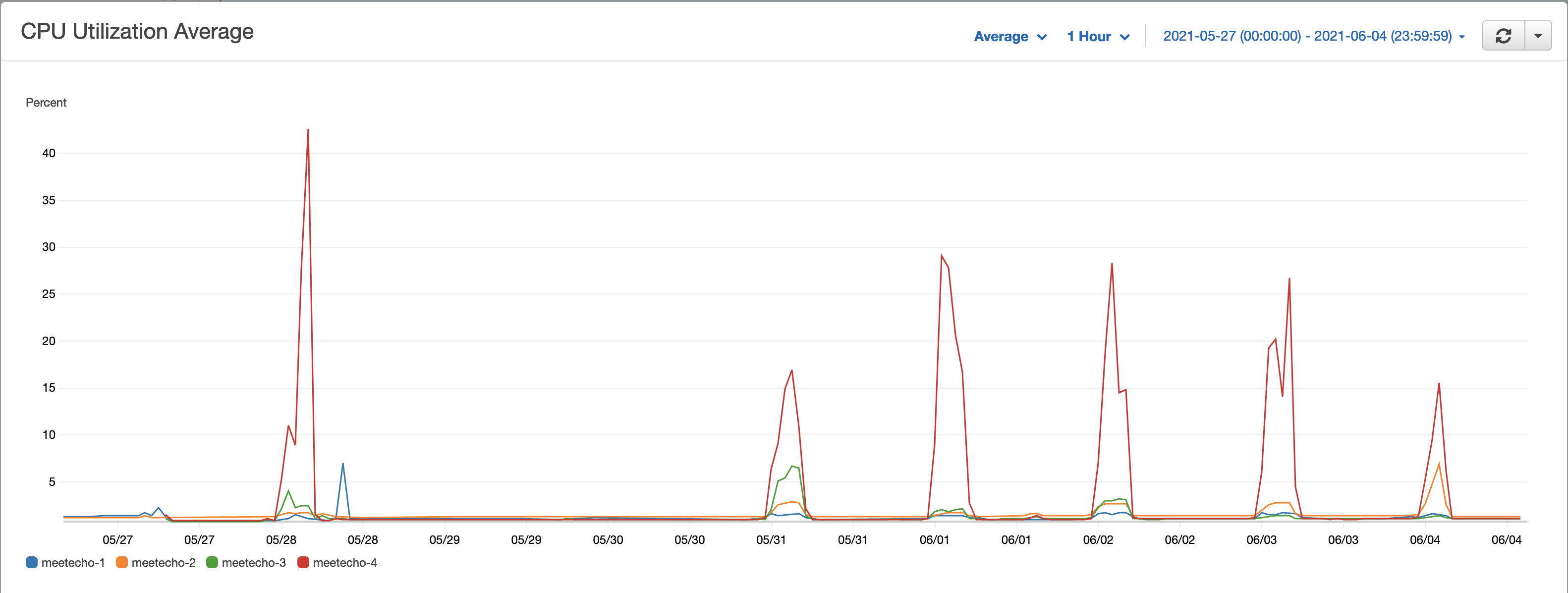
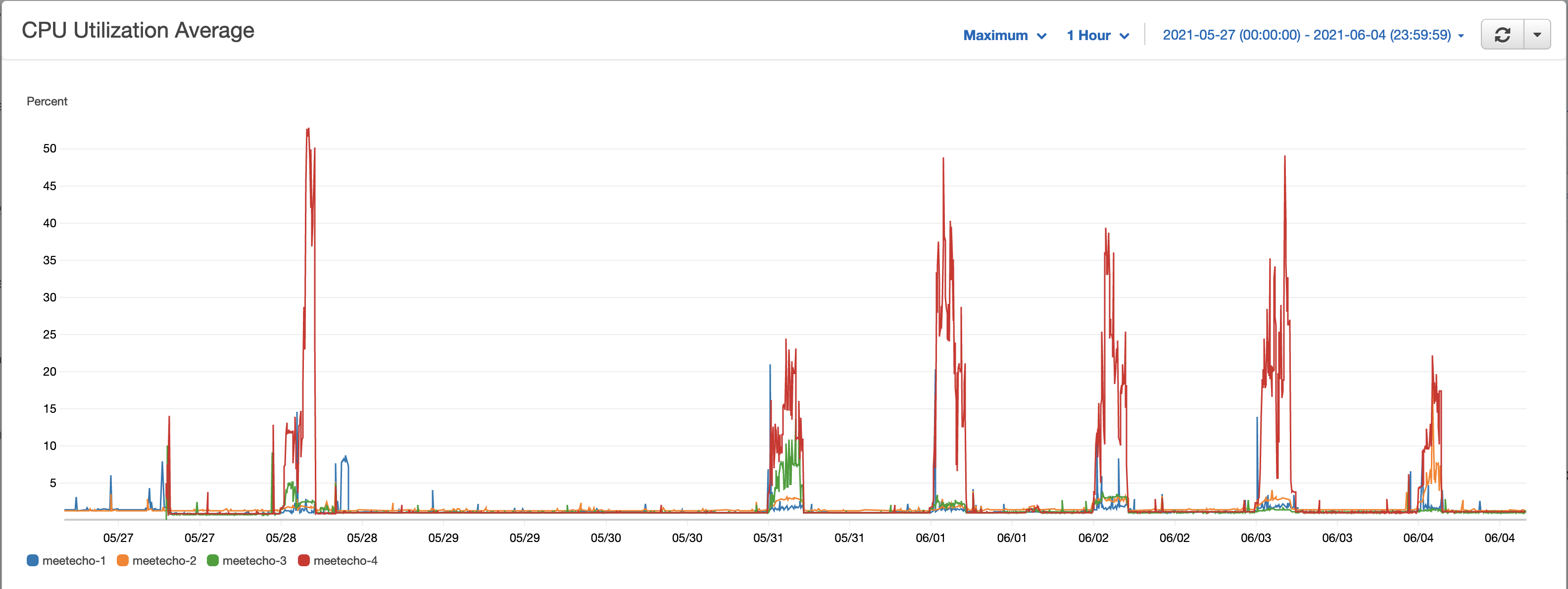
Technical Performance
The following graphs highlight how our infrastructure performed during our virtual meeting. As more people joined the meeting, the network usage started to peak on each day. On the first day, we got the highest network traffic.
Streaming also requires CPU power to process the video and audio, the highest CPU usage matches the first day where we saw the highest number of concurrent participants joining.
Meeting Partners and Sponsorship
It is important we acknowledge our AIS'21 Online Sponsors. This meeting was sponsored by ICANN, ISOC, dotAfrica, Flexoptix, Liquid Intelligent Technologies, Topdog and Emtel. We appreciate your continuous support.
What’s Next
AIS’21 Online was a rich learning experience for the whole AIS team who displayed a great team spirit. We are thankful to everyone who made this event a success as we look ahead to our next AIS/AFRINIC Meeting.
We shall also be happy to share our experience gained over the two online AIS meetings held with anyone who is interested in organising similar online events. The AIS organising team may be contacted at meeting [at] afrinic.net or comms [at] afrinic.net
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}